
Sepsis is a life-threatening conditions in which the body is failing to responds to an infection, causing the body’s organs to stop working. It stands as the leading cause of mortality for in house deaths in the ICU.
Sepsis is a very complex illness in which it typically stems from pre-existing comorbidities and underlying health conditions. While most sepsis cases (~80 percent) develop in the community and are present on arrival, the mortality rate for sepsis that develops while a patient is admitted, or is not present on arrival, is notably higher. One of the keys to sepsis treatment and survival lies in recognition and timely intervention/antibiotics.
Sepsis has been a medical challenge for centuries. The term "sepsis" is derived from the Greek word σῆψις, meaning decay or putrefaction, indicating the disease's destructive nature. The earliest recorded observations of sepsis date back to the writings of Hippocrates (circa 460–370 BC), who described the process of wound putrefaction and the systemic illness that followed. But for thousands of years, our basic knowledge of sepsis was limited, and many wrong ideas about it continued to exist.
Today's hospitals use advanced clinical criteria, laboratory testing, and technology to detect sepsis early. The implementation of SOFA and qSOFA scores aids in rapid assessment, while biomarkers like Procalcitonin and C-reactive protein provide key diagnostic insights. Point-of-care testing technologies enable bedside diagnostics, offering quicker intervention possibilities. Electronic Health Record (EHR) systems with integrated sepsis detection algorithms play a crucial role in identifying sepsis signs early, and antimicrobial stewardship programs ensure effective and responsible use of antibiotics to treat sepsis.
The evolution from historical misconceptions to current evidence-based practices highlights the significant strides made in sepsis detection and management, emphasizing the critical role of early detection and timely, appropriate treatment in improving patient outcomes.
source: https://www.ebmedicine.net/topics/infectious-disease/sepsis-septic-shock
Machine learning (ML) has emerged as a transformative force in medical diagnostics, offering unprecedented predictive power and diagnostic accuracy. By analyzing vast datasets, ML algorithms can identify patterns and correlations that elude human detection, facilitating early diagnosis and personalized treatment plans. In sepsis detection, ML models leverage electronic health records to predict sepsis onset hours before clinical symptoms manifest, significantly improving patient outcomes through timely intervention. This section highlights several ML models, including decision trees, support vector machines, and neural networks, showcasing their potential in advancing medical research and patient care.
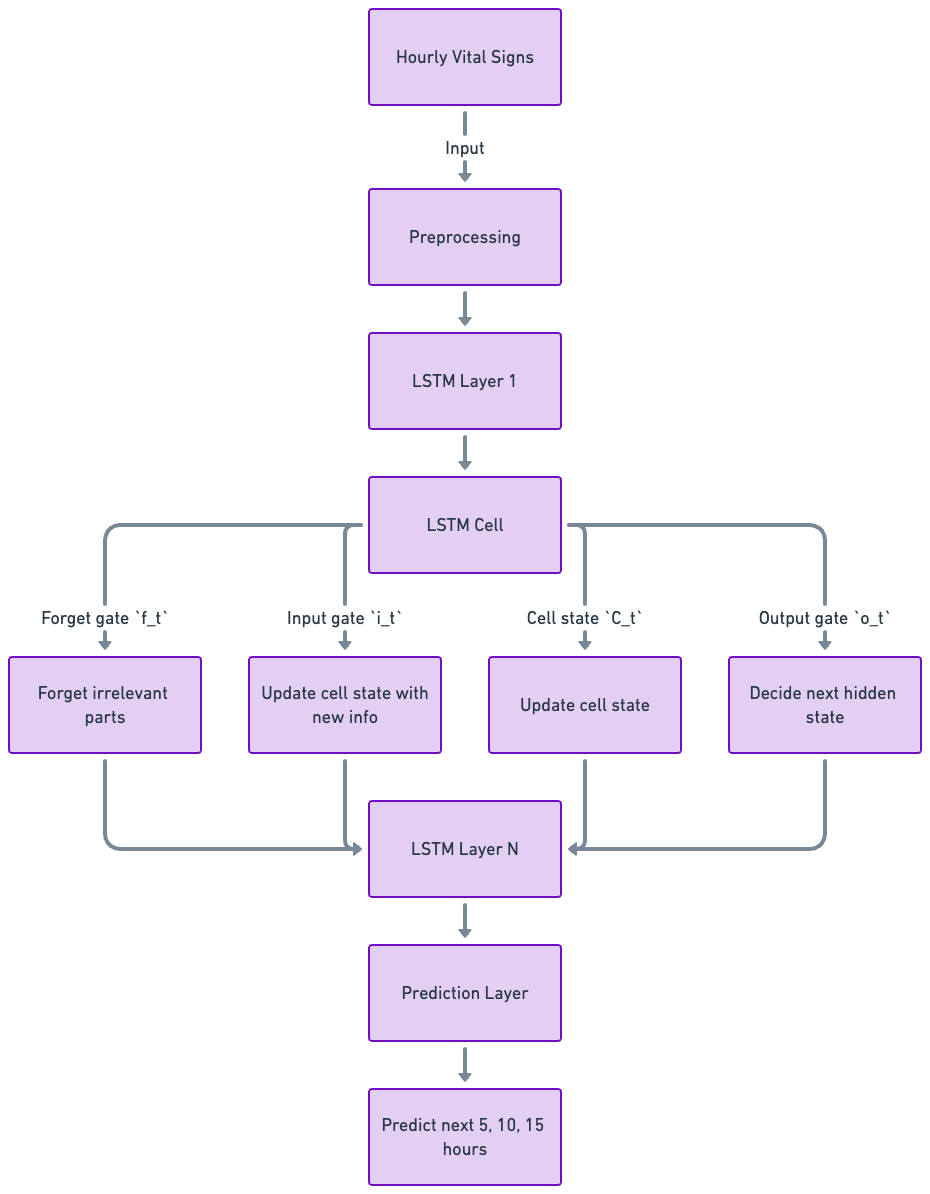
The Long Short-Term Memory (LSTM) model is a type of recurrent neural network (RNN) architecture that is specifically designed to address the challenge of learning long-term dependencies in data sequences. Unlike standard RNNs, which struggle with the vanishing gradient problem, LSTMs incorporate a series of gates—namely, the input, output, and forget gates—that regulate the flow of information. These gates effectively allow the model to decide which information is important to retain or discard over long sequences, making LSTMs particularly adept at processing and predicting outcomes based on time-series data.
Below diagram illustrates a Long Short-Term Memory (LSTM) network, a type of recurrent neural network (RNN) used to analyze and predict sequences of data. The process starts with the input of hourly vital signs data, which undergoes preprocessing to become suitable for analysis. The prepared data then passes through several LSTM layers. The 'forget gate' decides which parts of the data are not important and should be discarded. The 'input gate' allows the addition of new information to the cell state, updating it with relevant data. The cell state itself carries information through the chain of LSTM cells, ensuring that the network can maintain information over time. The 'output gate' determines what the next hidden state should be. This hidden state carries information to the next LSTM cell or layer. After the data passes through multiple LSTM layers (LSTM Layer 1 to LSTM Layer N), each adding complexity and depth to the analysis, the final LSTM layer outputs data to a prediction layer. This prediction layer utilizes the processed and analyzed information to make forecasts about future vital signs at intervals of 5, 10, and 15 hours.
TensorFlow and Keras
Adam
MIMIC III dataset
We explored several configurations of LSTM units (50, 75, 100, 125, 150) and dropout rates (0.2, 0.3, 0.4) to identify the optimal setup for our model. The final model architecture was selected based on its performance on the validation set, with a focus on maximizing recall to ensure the identification of as many true sepsis cases as possible, considering the critical nature of the condition.

Confusion Matrix for predicting 5 hours ahead of time
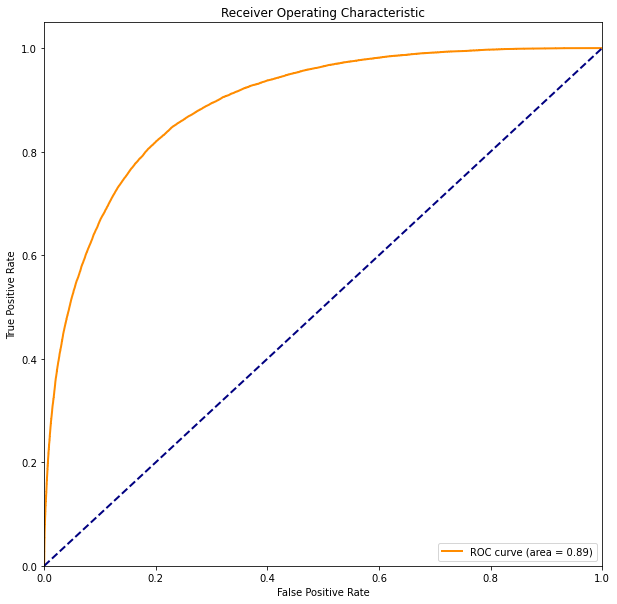
The area under the curve (AUC): The closer the curve is to the top left corner (closer to 1), the higher the accuracy of the test since it means high true positive rate and low false positive rate. In our case, Area Under the Receiver Operat- ing Characteristic (AUROC) curve reached 0.89, which can be considered as a good model.
| 5 Hrs | 10 Hrs | 15 Hrs | 20 Hrs | 25 Hrs | 50 Hrs | |
|---|---|---|---|---|---|---|
| Accuracy | 80.9% | 79.6% | 77.9% | 77.6% | 77.6% | 75.1% |
| Recall | 81.4% | 78.5% | 78.1% | 75.1% | 74.4% | 67.9% |
| F1 Score | 68.4% | 71.2% | 71.8% | 72.4% | 73.0% | 70.2% |
| Precision | 58.9% | 65.2% | 66.5% | 69.9% | 71.7% | 72.6% |
Results for predictions N hours ahead of time
To ensure the fairness and reliability of our predictive model, a critical step undertaken was the balancing of the dataset. Given the inherent imbalance in medical datasets—where instances of sepsis are considerably rarer compared to non-sepsis cases—unadjusted, this skew could lead to a model biased towards predicting the majority class, thus undermining its clinical utility. For every training epoch, we ensured an equal distribution of sepsis and non-sepsis labels presented to the model, thereby maintaining balance in the learning process. Upon the completion of each epoch, we shuffled the predominant non-sepsis data with fresh instances. This approach guaranteed that our model was exposed to a varied set of data points, while still preserving balanced label representation throughout the training phase.
When choosing our features, we decided to go with the four vital signs listed on the UCSD inpatient protocol, or SBAR (Situation, Background, Assessment, Recommendation), and blood pressure, heart rate, respiration rate, and body temperature are criteria for suspected infection. Even though these vital signs are crucial to determining sepsis, other measure- ments could be utilized to better train the model, including blood pressure (Mean Arterial Pressure), platelets, and lactate levels. We could add these measurements to our data for future improvements on the model. Another concern is that MIMIC-III dataset is from Beth Israel Deaconess Medical Center between 2001 and 2012, and the protocol we used to extract features from the dataset in from present day UC San Diego Medical Center - Hillcrest Campus. This is a potential issue when it comes to assign labels (with sepsis and without sepsis). In the future, it would be beneficial to switch to UCSD in-house electronic medical records for a match between data and protocol.